
whisper-timestamped
具有词级时间戳和置信度的多语言自动语音识别。
描述
Whisper 是由OpenAI训练的一组多语言、稳健的语音识别模型,在许多语言中都达到了最先进的效果。Whisper模型被训练来预测语音片段的大致时间戳(大多数情况下精确到1秒),但它们最初并不能预测词级时间戳。这个代码库提供了一个实现,用于在使用Whisper模型转录时预测词级时间戳并提供更准确的语音片段估计。 此外,每个词和每个片段都会被分配一个置信度分数。
该方法基于应用于交叉注意力权重的动态时间规整(DTW),正如Jong Wook Kim的这篇notebook所展示的那样。这个notebook有一些补充:
- 开始/结束时间的估计更加准确。
- 置信度分数被分配给每个单词。
- 如果可能(没有波束搜索...),不需要额外的推理步骤来预测单词时间戳(单词对齐在每个语音片段解码后立即完成)。
- 特别注意了内存使用:与常规使用Whisper模型相比,
whisper-timestamped能够以很少的额外内存处理长文件。
whisper-timestamped是openai-whisper Python包的扩展,旨在与任何版本的openai-whisper兼容。 它提供了更高效/准确的单词时间戳,以及以下附加功能:
- 可以在应用Whisper模型之前运行语音活动检测(VAD),以避免由于训练数据中的错误而导致的幻觉(例如,在纯粹的沉默中预测"Thanks you for watching!")。 有几种VAD方法可用:silero(默认),auditok,auditok:v3.1
- 如果未指定语言,则会在输出中提供语言概率。
免责声明:请注意,此扩展旨在用于实验目的,可能会严重影响性能。我们不对因使用它而引起的任何问题或效率低下负责。
其他方法说明
恢复单词级时间戳的一种相关替代方法是使用预测字符的wav2vec模型,这在whisperX中得到了成功实现。然而,这些方法存在一些缺点,而这些缺点在基于交叉注意力权重的方法(如whisper_timestamped)中并不存在。这些缺点包括:
- 需要为每种语言找到一个wav2vec模型来支持,这无法很好地适应Whisper的多语言能力。
- 需要处理(至少)一个额外的神经网络(wav2vec模型),这会消耗内存。
- 需要将Whisper转录中的字符规范化以匹配wav2vec模型的字符集。这涉及复杂的语言相关转换,例如将数字转换为单词("2" -> "two"),将符号转换为单词("%" -> "percent","€" -> "euro(s)")...
- 在处理语音不流畅部分(填充词、犹豫、重复词等)时缺乏稳健性,这些通常会被Whisper删除。
另一种不需要额外模型的方法是查看Whisper模型在预测每个(子)单词标记后估计的时间戳标记概率。这种方法已在whisper.cpp和stable-ts等项目中得到实现。然而,这种方法缺乏稳健性,因为Whisper模型并未经过训练来在每个单词后输出有意义的时间戳。Whisper模型倾向于仅在预测了一定数量的单词后才预测时间戳(通常是在句子结尾),而在这种条件之外的时间戳概率分布可能不准确。在实践中,这些方法可能在某些时间段内产生完全不同步的结果(我们特别在有背景音乐时观察到这种情况)。此外,Whisper模型的时间戳精度往往会四舍五入到1秒(就像许多视频字幕一样),这对于单词级别来说太不准确了,而且很难达到更好的精度。
安装
首次安装
系统要求:
python3(版本需3.7以上,建议至少3.9)ffmpeg(安装说明请参考whisper仓库)
您可以通过pip安装whisper-timestamped:
或者通过克隆仓库并运行安装:
可能需要的额外包
如果你想绘制音频时间戳和文字之间的对齐图(如本节所示),你还需要安装matplotlib:
如果你想使用VAD选项(在运行Whisper模型前进行语音活动检测),你还需要安装torchaudio和onnxruntime:
如果你想使用来自Hugging Face Hub的微调Whisper模型,你还需要安装transformers:
Docker
可以使用以下命令构建一个约9GB的docker镜像:
CPU轻量级安装
如果你没有GPU(或不想使用GPU),那么你不需要安装CUDA依赖。你应该在安装whisper-timestamped之前先安装torch的轻量版本,例如:
也可以使用以下命令构建一个约3.5GB的特定docker镜像:
升级到最新版本
使用pip时,可以通过以下命令将库更新到最新版本:
例如,可以通过运行以下命令来使用特定版本的openai-whisper:
使用方法
Python
在Python中,你可以使用whisper_timestamped.transcribe()函数,它与whisper.transcribe()函数类似:
与whisper.transcribe()的主要区别在于,输出结果中所有片段都会包含一个"words"键,其中包含每个单词的开始和结束位置。注意,单词会包含标点符号。请参见下方的示例。
此外,默认的解码选项也不同,更倾向于高效解码(使用贪婪解码而不是波束搜索,且没有温度采样回退)。如果要使用与whisper相同的默认设置,请使用beam_size=5, best_of=5, temperature=(0.0, 0.2, 0.4, 0.6, 0.8, 1.0)。
还有一些与单词对齐相关的额外选项。
通常,如果你在Python脚本中使用whisper_timestamped替代whisper,并使用transcribe(model, ...)替代model.transcribe(...),就能完成工作:
注意,你可以通过使用whisper_timestamped的load_model方法来使用来自HuggingFace或本地文件夹的微调Whisper模型。例如,如果你想使用whisper-large-v2-nob,只需要这样做:
命令行
你也可以在命令行中使用 whisper_timestamped,使用方式类似于 whisper。通过以下命令查看帮助:
与 whisper CLI 的主要区别如下:
- 输出文件:
- 输出的 JSON 包含单词时间戳和置信度分数。参见下文示例。
- 增加了 CSV 输出格式。
- 对于 SRT、VTT、TSV 格式,将会额外保存包含单词时间戳的文件。
- 一些默认选项的不同:
- 默认情况下没有设置输出文件夹:使用
--output_dir .来使用 Whisper 的默认设置。 - 默认情况下不显示详细信息:使用
--verbose True来使用 Whisper 的默认设置。 - 默认情况下,为了提高效率,禁用了波束搜索解码和温度采样回退。
要使用与 Whisper 相同的默认设置,可以使用--accurate(这是--beam_size 5 --temperature_increment_on_fallback 0.2 --best_of 5的别名)。
- 默认情况下没有设置输出文件夹:使用
- 有一些额外的特定选项:
--compute_confidence用于启用/禁用每个单词的置信度分数计算。--punctuations_with_words用于决定是否将标点符号包含在前面的单词中。
下面是一个使用 tiny 模型处理多个文件并将结果输出到当前文件夹的示例命令(这与 whisper 的默认行为相同):
注意,你可以使用来自 HuggingFace 或本地文件夹的微调 Whisper 模型。例如,如果你想使用 whisper-large-v2-nob 模型,只需执行以下操作:
实用函数
除了主要的 transcribe 函数外,whisper-timestamped 还提供了一些实用函数:
remove_non_speech
使用语音活动检测(VAD)移除音频中的非语音片段。
load_model
从给定的名称或路径加载 Whisper 模型,包括支持来自 HuggingFace 的微调模型。
单词对齐可视化
注意,你可以使用 whisper_timestamped.transcribe() Python 函数的 plot_word_alignment 选项或 whisper_timestamped CLI 的 --plot 选项来查看每个片段的单词对齐情况。
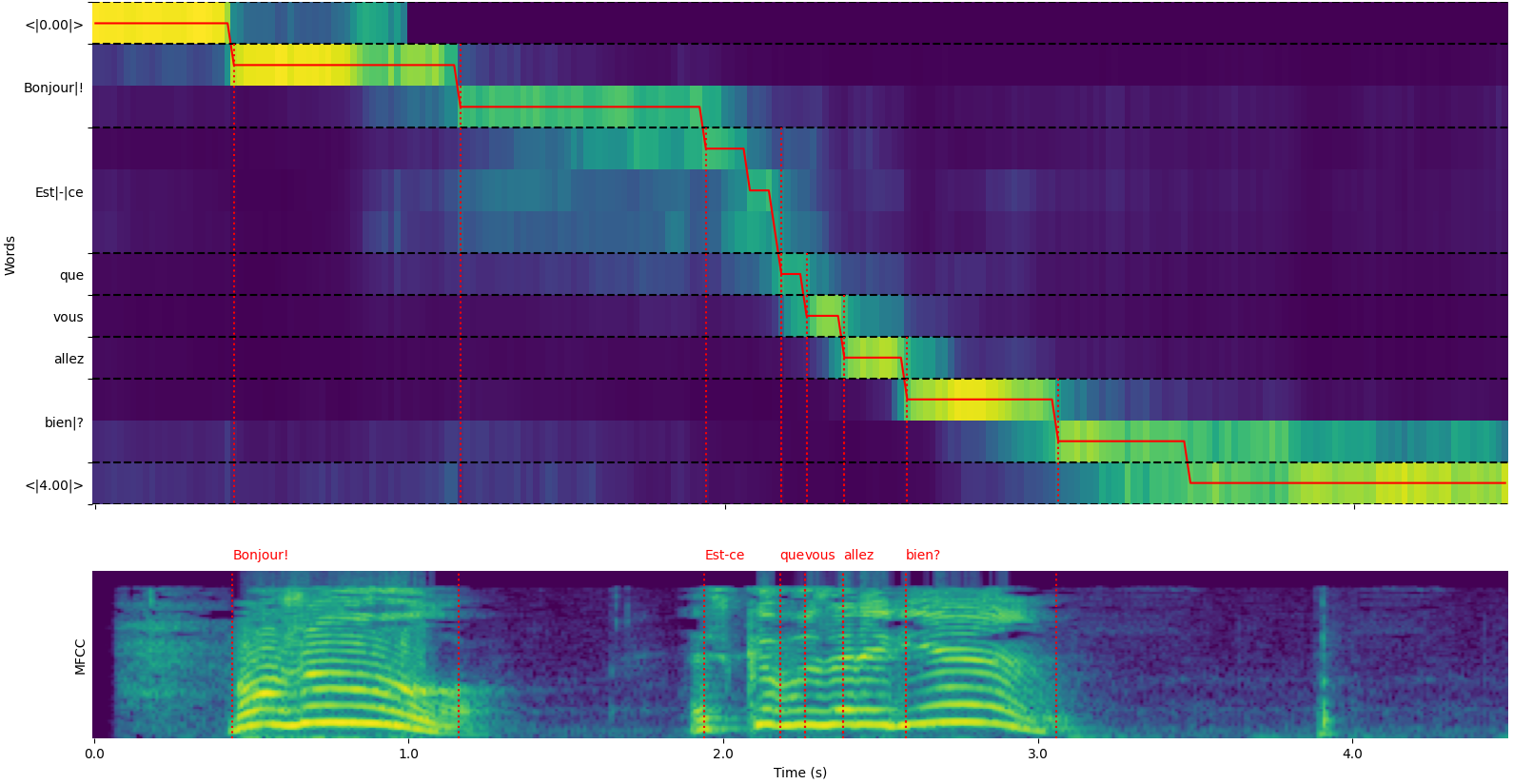
- 上方的图表表示用于通过动态时间规整进行对齐的交叉注意力权重的转换。横轴表示时间,纵轴表示预测的标记,包括开始和结束处的特殊时间戳标记,以及中间的(子)单词和标点符号。
- 下方的图表是输入信号的 MFCC 表示(Whisper 使用的基于梅尔频率倒谱的特征)。
- 垂直的红色虚线显示了单词边界的位置(标点符号"粘附"在前一个单词上)。
示例输出
whisper_timestamped.transcribe() 函数的输出是一个 Python 字典, 可以通过 CLI 以 JSON 格式查看。
JSON 模式可以在 tests/json_schema.json 中查看。
以下是一个示例输出:
如果未指定语言(例如在 CLI 中没有使用 --language fr 选项),你将在输出中找到一个额外的键,其中包含语言检测概率:
API 参考
主要转录函数
transcribe_timestamped(model, audio, **kwargs)
使用 Whisper 模型转录音频并计算词级时间戳。
参数:
-
model: Whisper 模型实例
用于转录的 Whisper 模型。 -
audio: Union[str, np.ndarray, torch.Tensor]
要转录的音频文件路径,或作为 NumPy 数组或 PyTorch 张量的音频波形。 -
language: str, 可选 (默认值: None)
音频的语言。如果为 None,将进行语言检测。 -
task: str, 默认值 "transcribe"
要执行的任务:"transcribe" 用于语音识别,或 "translate" 用于翻译成英语。 -
vad: Union[bool, str, List[Tuple[float, float]]], 可选 (默认值: False)
是否使用语音活动检测(VAD)来移除非语音片段。可以是:- True/False:启用/禁用 VAD(默认使用 Silero VAD)
- "silero":使用 Silero VAD
- "auditok":使用 Auditok VAD
- (start, end) 时间戳列表:明确指定语音片段
-
detect_disfluencies: bool, 默认值 False
是否在转录中检测和标记不流畅(犹豫、填充词等)。 -
trust_whisper_timestamps: bool, 默认值 True
是否依赖 Whisper 的时间戳作为初始片段位置。 -
compute_word_confidence: bool, 默认值 True
是否计算词的置信度分数。 -
include_punctuation_in_confidence: bool, 默认值 False
计算词置信度时是否包含标点符号概率。 -
refine_whisper_precision: float, 默认值 0.5
细化 Whisper 片段位置的程度(以秒为单位)。必须是 0.02 的倍数。 -
min_word_duration: float, 默认值 0.02
单词的最小持续时间(以秒为单位)。 -
plot_word_alignment: bool 或 str, 默认值 False
是否为每个片段绘制词对齐图。如果是字符串,则将图保存到指定文件。 -
word_alignement_most_top_layers: int, 可选 (默认值: None)
用于词对齐的顶层数量。如果为 None,使用所有层。 -
remove_empty_words: bool, 默认值 False
是否移除片段末尾出现的无持续时间的词。 -
naive_approach: bool, 默认值 False
强制使用朴素方法进行两次解码(一次用于转录,一次用于对齐)。 -
use_backend_timestamps: bool, 默认值 False
是否使用后端(openai-whisper 或 transformers)提供的词时间戳,而不是使用 whisper-timestamped 的更复杂启发式计算结果。 -
temperature: Union[float, List[float]], 默认值 0.0
采样温度。可以是单个值或用于回退的温度列表。 -
compression_ratio_threshold: float, 默认值 2.4
如果 gzip 压缩比高于此值,则将解码视为失败。 -
logprob_threshold: float, 默认值 -1.0
如果平均对数概率低于此值,则将解码视为失败。 -
no_speech_threshold: float, 默认值 0.6
<|nospeech|> 标记的概率阈值。 -
condition_on_previous_text: bool, 默认值 True
是否将前一个输出作为下一个窗口的提示。 -
initial_prompt: str, 可选 (默认值: None)
为第一个窗口提供的可选文本提示。 -
suppress_tokens: str, 默认值 "-1"
在采样过程中要抑制的标记 ID 列表,以逗号分隔。 -
fp16: bool, 可选 (默认值: None)
是否以 fp16 精度进行推理。 -
verbose: bool 或 None, 默认值 False
是否在控制台显示正在解码的文本。如果为 True,显示所有详细信息。如果为 False,显示最少详细信息。如果为 None,不显示任何信息。
返回值:
包含以下内容的字典:
text: str - 完整的转录文本segments: List[dict] - 片段字典列表,每个字典包含:id: int - 片段 IDseek: int - 音频文件中的起始位置(以样本为单位)start: float - 片段开始时间(秒)end: float - 片段结束时间(秒)text: str - 片段的转录文本tokens: List[int] - 片段的标记 IDtemperature: float - 用于此片段的温度avg_logprob: float - 片段的平均对数概率compression_ratio: float - 片段的压缩比no_speech_prob: float - 片段中无语音的概率confidence: float - 片段的置信度分数words: List[dict] - 词字典列表,每个字典包含:start: float - 词的开始时间(秒)end: float - 词的结束时间(秒)text: str - 词文本confidence: float - 词的置信度分数(如果计算)
language: str - 检测到的或指定的语言language_probs: dict - 语言检测概率(如果适用)
异常:
RuntimeError: 如果 VAD 方法未正确安装或配置。ValueError: 如果refine_whisper_precision不是 0.02 的正倍数。AssertionError: 如果音频持续时间短于预期或片段数量不一致。
注意事项:
- 该函数使用 Whisper 模型转录音频,然后进行额外处理以生成词级时间戳和置信度分数。
- VAD 功能通过移除非语音片段可以显著提高转录准确性,但需要额外的依赖项(例如,Silero VAD 需要 torchaudio 和 onnxruntime)。
naive_approach参数在调试或处理特定音频特征时可能有用,但可能比默认方法慢。- 当
use_efficient_by_default为 True 时,一些参数如best_of、beam_size和temperature_increment_on_fallback默认设置为 None 以提高处理效率。 - 该函数支持 OpenAI Whisper 和 Transformers 后端,可以在加载模型时指定。
工具函数
remove_non_speech(audio, **kwargs)
使用语音活动检测(VAD)从音频中移除非语音段。
参数:
-
audio: torch.Tensor
作为PyTorch张量的音频数据。 -
use_sample: bool, 默认值 False
如果为True,则以采样点而不是秒为单位返回开始和结束时间。 -
min_speech_duration: float, 默认值 0.1
语音段的最小持续时间(秒)。 -
min_silence_duration: float, 默认值 1
静音段的最小持续时间(秒)。 -
dilatation: float, 默认值 0.5
VAD检测到的每个语音段的扩展时间(秒)。 -
sample_rate: int, 默认值 16000
音频的采样率。 -
method: str 或 List[Tuple[float, float]], 默认值 "silero"
使用的VAD方法。可以是"silero"、"auditok"或时间戳列表。 -
avoid_empty_speech: bool, 默认值 False
如果为True,避免返回空的语音段。 -
plot: Union[bool, str], 默认值 False
如果为True,绘制VAD结果。如果是字符串,则将图表保存到指定文件。
返回值:
包含以下内容的元组:
- torch.Tensor: 移除非语音段后的音频
- List[Tuple[float, float]]: 语音段的(开始,结束)时间戳列表
- Callable: 用于将新音频的时间戳转换为原始音频时间戳的函数
异常:
ImportError: 如果未安装所需的VAD库(如auditok)。ValueError: 如果指定了无效的VAD方法。
注意:
- 此函数特别适用于通过在处理前移除静音和非语音段来提高转录准确性。
- VAD方法的选择会影响非语音移除过程的准确性和速度。
load_model(name, device=None, backend="openai-whisper", download_root=None, in_memory=False)
从给定的名称或路径加载Whisper模型。
参数:
-
name: str
模型名称或路径。可以是:- OpenAI Whisper标识符:"large-v3"、"medium.en"等
- HuggingFace标识符:"openai/whisper-large-v3"、"distil-whisper/distil-large-v2"等
- 文件名:"path/to/model.pt"、"path/to/model.ckpt"、"path/to/model.bin"
- 文件夹名:"path/to/folder"
-
device: Union[str, torch.device], 可选(默认值:None)
使用的设备。如果为None,则在可用时使用CUDA,否则使用CPU。 -
backend: str, 默认值 "openai-whisper"
使用的后端。可以是"transformers"或"openai-whisper"。 -
download_root: str, 可选(默认值:None)
下载模型的根文件夹。如果为None,使用默认下载根目录。 -
in_memory: bool, 默认值 False
是否将模型权重预加载到主机内存中。
返回值:
加载的Whisper模型。
异常:
ValueError: 如果指定了无效的后端。ImportError: 如果使用"transformers"后端时未安装transformers库。RuntimeError: 如果无法从指定源找到或下载模型。OSError: 如果读取模型文件或访问指定路径时出现问题。
注意:
- 使用本地模型文件时,确保文件格式与所选后端兼容。
- 对于HuggingFace模型,如果模型未在本地缓存,可能需要互联网连接来下载。
- 该函数支持加载OpenAI Whisper和Transformers模型,提供了模型选择的灵活性。
get_alignment_heads(model, max_top_layer=3)
获取给定模型的对齐头。
参数:
-
model: Whisper模型实例
需要获取对齐头的Whisper模型。 -
max_top_layer: int, 默认值 3
考虑对齐头的最大顶层数量。
返回值:
表示对齐头的稀疏张量。
注意:
- 此函数在内部用于优化词级别对齐过程。
- 对齐头是特定于模型的,用于提高词级别时间戳的准确性。
文件写入函数
以下函数可用于将转录内容写入各种文件格式:
write_csv(transcript, file, sep=",", text_first=True, format_timestamps=None, header=False)
将转录数据写入CSV文件。
参数:
-
transcript: List[dict]
转录段落字典的列表。 -
file: file-like object
用于写入CSV数据的文件对象。 -
sep: str, 默认值 ","
CSV文件中使用的分隔符。 -
text_first: bool, 默认值 True
如果为True,在开始/结束时间之前写入文本列。 -
format_timestamps: Callable, 可选(默认值:None)
用于格式化时间戳值的函数。 -
header: Union[bool, List[str]], 默认值 False
如果为True,写入默认表头。如果是列表,则用作自定义表头。
异常:
IOError: 如果写入指定文件时出现问题。ValueError: 如果转录数据不符合预期格式。
注意:
- 此函数适用于将转录结果导出为表格格式,以便进行进一步分析或处理。
format_timestamps参数允许自定义时间戳值的格式,这对特定用例或数据分析要求很有帮助。
write_srt(transcript, file)
将转录数据写入SRT(SubRip字幕)文件。
参数:
-
transcript: List[dict]
转录段落字典的列表。 -
file: file-like object
用于写入SRT数据的文件对象。
异常:
IOError: 如果写入指定文件时出现问题。ValueError: 如果转录数据不符合预期格式。
注意:
- SRT是一种广泛支持的字幕格式,使此函数适用于根据转录创建视频字幕。
write_vtt(transcript, file)
将转录数据写入VTT(WebVTT)文件。
参数:
-
transcript: List[dict]
转录段落字典的列表。 -
file: file-like object
用于写入VTT数据的文件对象。
异常:
IOError: 如果写入指定文件时出现问题。ValueError: 如果转录数据不符合预期格式。
注意:
- WebVTT是W3C用于在HTML5中显示定时文本的标准,使此函数适用于基于Web的应用程序。
write_tsv(transcript, file)
将转录数据写入TSV(制表符分隔值)文件。
参数:
-
transcript: List[dict]
转录段落字典的列表。 -
file: file-like object
用于写入TSV数据的文件对象。
异常:
IOError: 如果写入指定文件时出现问题。ValueError: 如果转录数据不符合预期格式。
注意:
- TSV文件对于将转录数据导入电子表格应用程序或其他数据分析工具很有用。
可以改进结果的选项
以下是一些默认未启用但可能改进结果的选项。
提高Whisper转录准确性
如前所述,某些解码选项默认被禁用以提供更好的效率。然而,这可能会影响转录的质量。要使用最有可能提供良好转录的选项,请使用以下设置。
- 在Python中:
- 在命令行中:
在发送到Whisper之前运行语音活动检测(VAD)
当给定没有语音的片段时,Whisper模型可能会"产生幻觉"文本。这可以通过在使用Whisper模型转录之前运行VAD并将语音片段粘合在一起来避免。使用whisper-timestamped可以实现这一点。
- 在Python中:
- 在命令行中:
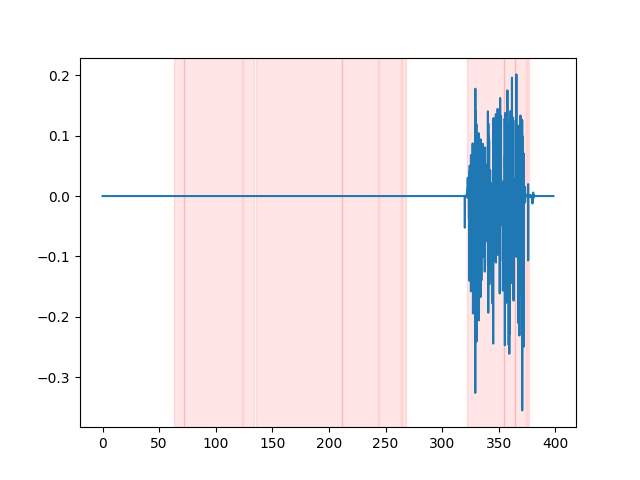
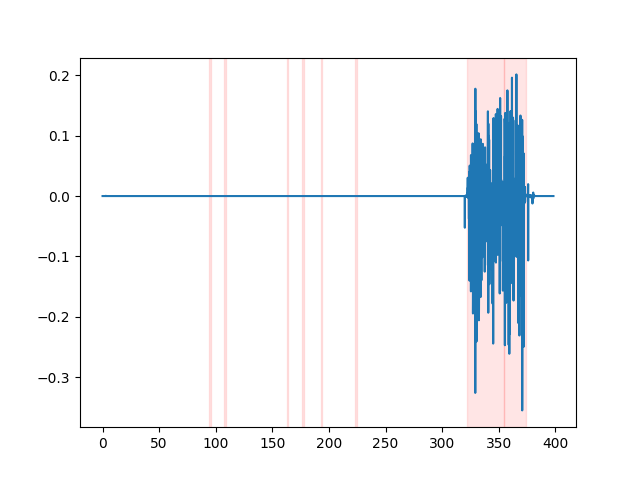
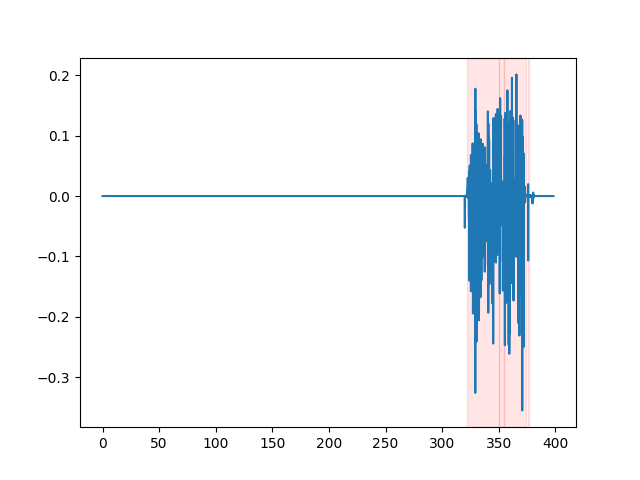
默认使用的VAD方法是silero。 但也可以使用其他方法,比如silero的早期版本,或者auditok。 引入这些方法是因为silero VAD的最新版本在某些音频上可能会产生大量误报(在静音部分检测到语音)。
- 在Python中:
- 在命令行中:
要查看VAD结果,你可以使用whisper_timestamped CLI的--plot选项, 或者使用whisper_timestamped.transcribe() Python函数的plot_word_alignment选项。 它将在输入音频信号上显示VAD结果,如下所示(x轴为时间,单位为秒):
| vad="silero:v4.0" | vad="silero:v3.1" | vad="auditok" |
|---|---|---|
 |
 |
 |
检测不流畅
Whisper模型倾向于删除语音中的不流畅部分(填充词、犹豫、重复等)。如果不采取预防措施,未被转录的不流畅部分会影响后续单词的时间戳:单词开始的时间戳实际上会是不流畅部分开始的时间戳。whisper-timestamped可以使用一些启发式方法来避免这种情况。
- 在Python中:
- 在命令行中:
重要提示: 请注意,当使用这些选项时,可能的不流畅部分将在转录中显示为特殊的"[*]"词。
致谢/支持
whisper-timestamped 主要由 Jérôme Louradour 编写。 该项目基于以下库:
- whisper: Whisper 语音识别 (MIT 许可证)
- dtw-python: 动态时间规整 (GPL v3 许可证)



